Introduction
As AI becomes embedded in education, public discourse has focused heavily on misuse. Concerns about cheating, shortcuts, and academic integrity dominate policy and media narratives. This report examines a different question: how are students actually using AI when they are trying to learn?
Using data from 4,910,114 graded messages sent by 144,544 students on StudyFetch between January 20 and March 10, 2026, we analyze how students communicate with AI, how that communication affects their outcomes, and what this reveals about the emerging skill of AI literacy. Every message was scored in real time on two independent dimensions, prompting and responsibility, using the AI Literacy rubric built into StudyFetch's Spark.E AI tutor.6
The picture that emerges runs counter to the dominant narrative. Students are not approaching AI as a shortcut; they overwhelmingly approach it as a tool for learning. What they struggle with is much more ordinary: they cannot consistently tell the AI what they actually need. And that deficit, not any ethical one, is where the learning gap is opening up.
Students know how to use AI responsibly. They do not yet know how to use it effectively. The gap is not ethical. It is technical, and unlike most structural challenges in education, this one appears to be solvable.
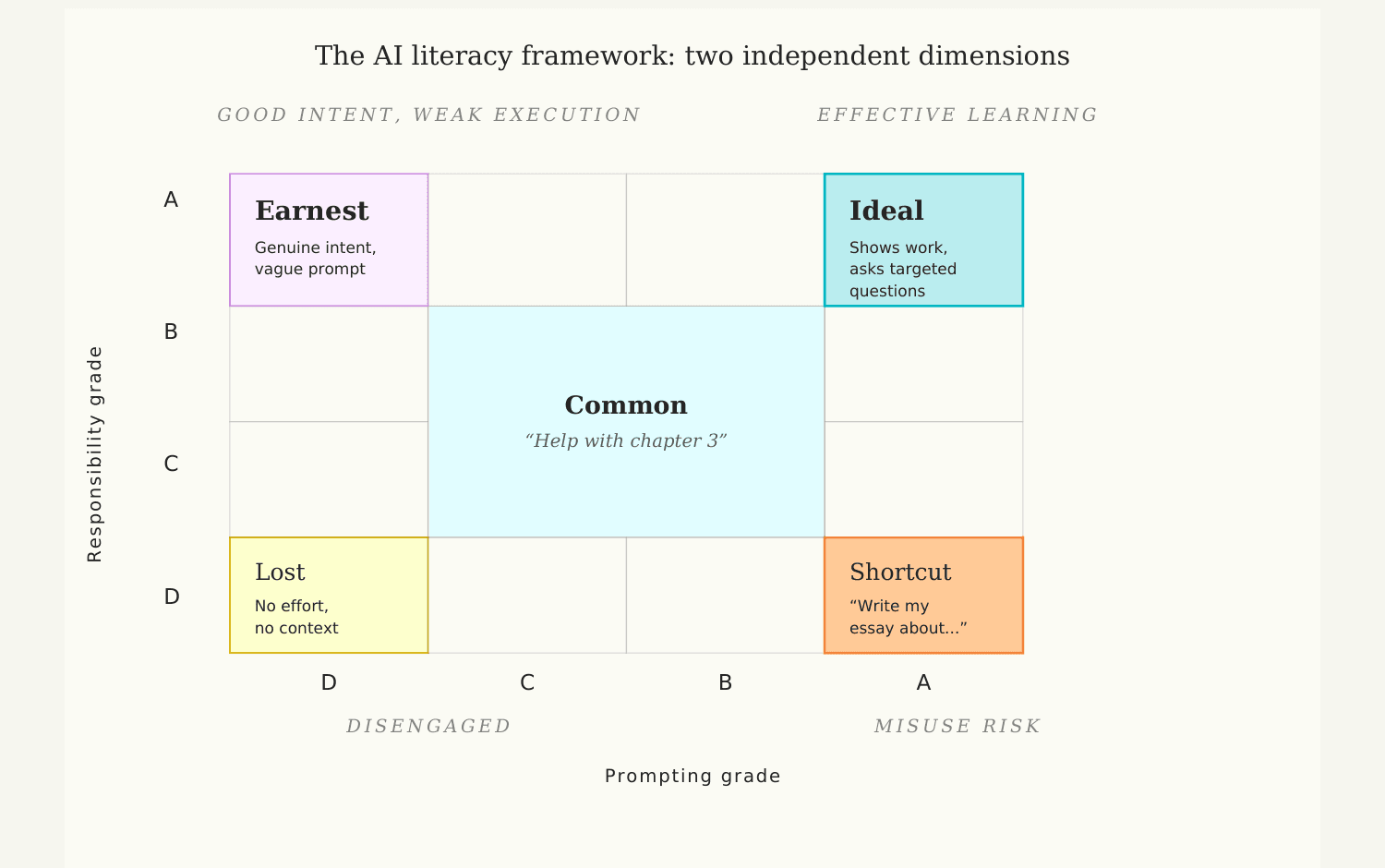
The AI literacy framework: two independent dimensions
To understand student behavior at scale, we developed an AI Literacy framework built around two independent dimensions:
- Prompting — how clearly a student communicates intent and provides context.
- Responsibility — whether a student uses AI to learn, or to bypass learning.
Each graded interaction is scored on a 1–4 scale (A–D) across both dimensions, allowing us to observe behavior at a scale that traditional classroom assessment cannot reach. The dimensions are scored independently because they capture genuinely different failure modes. A student can write a flawlessly clear prompt that asks the AI to complete their essay (A on prompting, D on responsibility). Another can show deep engagement while being vague about what they actually need (A on responsibility, C on prompting). Separating the dimensions lets us diagnose the right problem.
What gets graded
Not every message needs a score. The system skips simple acknowledgements (“ok,” “thanks,” “got it”), very short messages, and quiz answer submissions. About 35% of messages fall into this category; the remaining 65% are graded in real time.6 Students see a per-message letter grade with pre-send coaching, and a rolling view of their last 100 messages so they can track their own progress.
Findings at scale
Students are not misusing AI
Across 4.9 million interactions from over 144,000 students, the data shows a consistent pattern:
92.9%
Messages scoring A or B on responsibility
0.08%
Flagged for dishonesty-related behavior
3,967
Flagged messages out of 4,910,114
Students are not approaching AI as a shortcut. They are using it as a tool to support learning. This challenges a central assumption in current education debates: the primary issue is not misuse, it is effectiveness. Our AI tutor does not give direct answers, which discourages shortcut behavior from repeating; the high responsibility rate reflects both student intent and product design. We cannot claim the same rate would hold on a general-purpose AI tool, but when the tool is built for learning, the overwhelming majority of students use it that way.1
The real gap: students cannot communicate effectively with AI
While responsibility is high, prompting ability is low. Only 0.5% of students with five or more graded messages consistently produce A-level prompts, and 55% of students average at a C or below on prompting across all their messages.2
A typical C-level interaction looks like this:
“Help with chapter 3.”
The AI must guess what the student actually needs. It usually guesses too broadly, and the student gets a generic response instead of the specific help they were looking for. In contrast, an A-level prompt provides context, demonstrates effort, and asks a targeted question:
“I'm working on a calculus problem where I need to find the derivative of f(x) = x³sin(x). I tried using the product rule and got 3x²sin(x) + x³cos(x). Can you check if that's right and explain why the product rule applies here?”
These interactions let the AI act as a tutor rather than a search engine. Almost nobody writes prompts like this, but the students who do get dramatically better results.
Education level does not close the gap
If prompting were simply a function of education or cognitive maturity, we would expect the gap to narrow by graduate school. It does not.
| Education level | Avg. prompting (of 4) | % A-level | % A or B |
|---|---|---|---|
| High School | 2.38 | 6.8% | 42.1% |
| College | 2.48 | 8.6% | 48.1% |
| Medical School | 2.50 | 9.2% | 49.2% |
| Graduate School | 2.52 | 9.6% | 50.5% |
Table 1. Average prompting performance by education level. Education level is self-reported during onboarding and is set for roughly 65% of graded messages. The modest upward trend with education suggests prompting is a learned skill, not a by-product of formal schooling.
Students at every stage know how to use AI ethically. They just cannot consistently tell it what they need.
How interaction quality affects learning outcomes
The difference between effective and ineffective AI use is measurable. In a study of 10,000 quiz questions where students used the Spark.E AI tutor during practice sessions, we compared performance across responsibility grades:8
- Students engaging at the highest level were 2.3× more likely to answer correctly on their first attempt (33.5% vs 14.5%).
- They were 2× more likely to master the material (54.4% vs 26.9%).
- Their average best grade was 21 points higher (63.6 vs 42.6).
The gap becomes most visible on free response questions, where guessing cannot rescue a student.
Learning occurs even when students are not aware of it
One of the more surprising findings is that AI-assisted learning occurs even when students lack confidence. At every confidence level, students who engaged with the AI performed better than those who did not.
These students had absorbed something from the interaction that they could not consciously feel. It suggests that learning is occurring during the AI interaction itself, even when students cannot immediately recognize it — an insight with implications both for how we measure AI-assisted learning and for how we design it.
AI literacy is a skill, and it improves quickly
Prompting ability is not fixed. Students improve rapidly with practice on the platform, and the improvement is not gradual — it happens in a sharp jump.
| Messages sent | Avg. prompting | % scoring C or better |
|---|---|---|
| 1–5 | 1.28 | 25% |
| 6–10 | 1.27 | 26% |
| 11–15 | 1.75 | 60% |
| 31–50 | 1.98 | 73% |
Table 2. Average prompting performance by cumulative messages sent. Something changes around messages 11 to 15. Students go from 26% of their messages reaching C-level to 60% in a single bucket, and the improvement holds through message 100.
Most students improve
Even for the students who start at the bottom, the trajectory is encouraging. In a cohort of 190 students who averaged below 1.5 on their first ten messages and went on to send 50 or more total messages, 87% moved up to at least C-level on their last twenty messages.10 A small sample, and some of the improvement likely reflects regression to the mean, but the sustained level through messages 31 to 100 suggests genuine learning.
The pattern suggests AI literacy is learnable, and that feedback loops — the kind StudyFetch bakes into every interaction — can meaningfully accelerate that learning.
AI literacy is associated with stronger academic performance
To examine whether AI literacy correlates with broader learning outcomes, we joined the AI literacy scores with performance data from StudyFetch's Learn Engine. The Learn Engine tracks how students master topics across the platform through an ELO-like scoring system: a mastery score (K-score) that goes up when students answer correctly and down when they don't, calibrated against question difficulty and other learners' performance. It currently covers over 30,000 active topic clusters and updates continuously across every interaction.12
We sampled 200 students per AI literacy grade (A, B, C, D) across both prompting and responsibility dimensions, ran the analysis 10 times, and averaged the results. We excluded topics that were created but never practiced. We measured each student's correct rate, mastery rate, average number of questions answered, K-score, and average streak length.
Prompting grade vs. performance
| Grade | Students | Avg. K-score | Correct rate | Mastery rate | Avg. questions | Avg. streak |
|---|---|---|---|---|---|---|
| A | 200 | 1600.9 | 71.1% | 28.0% | 150.0 | 3.56 |
| B | 200 | 1588.5 | 69.1% | 20.7% | 211.0 | 2.99 |
| C | 200 | 1579.1 | 65.3% | 19.9% | 174.2 | 2.68 |
| D | 200 | 1569.7 | 64.5% | 18.8% | 75.6 | 2.61 |
Table 3. Learn Engine performance by prompting grade. Correct rate, K-score, and mastery rate all decline monotonically from A to D. Mastery rate shows a 1.5× gap between A and D students.
Responsibility grade vs. performance
| Grade | Students | Avg. K-score | Correct rate | Mastery rate | Avg. questions | Avg. streak |
|---|---|---|---|---|---|---|
| A | 200 | 1605.3 | 72.1% | 24.9% | 158.5 | 3.31 |
| B | 200 | 1583.4 | 68.3% | 21.3% | 154.3 | 3.06 |
| C | 200 | 1573.5 | 67.8% | 20.6% | 109.8 | 2.86 |
| D | 63 | 1554.8 | 61.5% | 19.8% | 50.1 | 3.08 |
Table 4. Learn Engine performance by responsibility grade. The D-bucket contains only 63 students (11 with K-score data) because very few students consistently score D on responsibility — interpret with caution.13
Topic mastery and the engagement gap
The most striking finding in the Learn Engine analysis may not be the performance difference but the engagement difference.
Students who struggle to communicate with AI don't just perform worse. They practice less. Whether this is because poor AI interactions are discouraging, or because lower-engagement students also happen to be worse prompters, or both — the result is the same: the students who most need practice are getting the least of it.
This suggests a feedback loop worth naming explicitly:
Poor communication → weak AI responses → frustration → disengagement → fewer learning opportunities.
If this chain holds up under more rigorous study, teaching better prompting is not just an AI literacy intervention. It is a retention intervention, one that could compound across every subsequent AI interaction the student has, across every subject and every tool.
Even controlling for engagement, the gap persists
One possible explanation for the performance gap is that A-grade students simply practice more, and more practice leads to better scores. The mastery rate data complicates that story. On topics they actually practiced, A-grade prompting students master 28.0% of topics vs 18.8% for D-grade students, a 1.5× difference that cannot be explained by volume alone. If practice were the whole story, we would expect similar mastery rates per topic across grades, with A students just covering more topics. Instead, higher-literacy students are also more effective per topic.
A simple product-level fix: context
Students who attach study materials to their chats score +0.15 higher on prompting on average (2.53 vs 2.38).16Materials give the AI built-in context, which means even a short prompt like “quiz me on this” becomes effective. That is a useful product-level fix and it works, but the deeper fix is teaching students to provide that context themselves.
The baseline effect of using the tutor at all
Separate from how well students engage, using the AI tutor itself helps. Across the full dataset of 536,362 quiz questions where students opened the chat sidebar, students who got a question wrong and then chatted with the AI before retrying were more likely to answer correctly on their next attempt than students who retried without chatting. Students who opened the chat before their first answer attempt also got the question right at a substantially higher rate than the 22.1% baseline for students who answered cold.17
The tutor helps even when the student isn't engaging deeply, but the gap between “used the tutor” and “used the tutor well” is where the real learning difference appears.
What this means for education
Taken together, the findings suggest a shift in how AI should be approached in learning environments.
Students do not need to be taught to use AI responsibly. Most already do: 92.9% of messages score A or B on responsibility, and the education-level data shows no meaningful gap across high school, college, medical school, or graduate school. What they need is to be taught how to communicate with AI. That is a skill, like writing, like study skills, and the data suggests it is a skill that can be learned quickly when students get feedback.
This matters well beyond school. AI is becoming the interface for knowledge work. Students who cannot effectively interact with these systems are at a structural disadvantage, not because they lack intelligence or ethics, but because they have not yet been taught the communication technique that makes these tools useful. AI literacy is not optional. It is foundational.
The implication for product and curriculum is the same: move AI literacy instruction from a separate course into the flow of normal coursework. Every conversation with a tutor becomes a practice rep. Every message can carry corrective feedback before it is sent. Our AI literacy grading system already shows students real-time feedback on their prompting before they hit send; we are expanding that into dedicated prompt training tools, guided exercises, and classroom-level prompting analytics for teachers.
Limitations and future research
This analysis is based on observational data. Students were not randomly assigned to AI literacy grades. Several alternative explanations remain plausible:
- Higher-performing students may naturally produce better prompts, use AI more responsibly, and perform better on assessments, all independently. If that is the case, the AI literacy score reflects an underlying trait rather than a teachable skill that directly improves outcomes.
- Engagement levels may drive both prompting quality and outcomes.
- Motivation and prior knowledge may influence all observed variables simultaneously.
We cannot rule these out with observational data alone. To separate the effect of AI literacy from the effect of general ability, a controlled study is required: take students with similar baseline ability, teach some of them to prompt better, and measure whether their learning outcomes improve relative to a control group. That study has not been done yet. But the data makes a case that it should be.
We are actively seeking partnerships with social scientists and research institutions to test whether improving AI literacy directly improves learning outcomes. If you are a researcher interested in studying the causal link between AI literacy and learning outcomes, StudyFetch has the data infrastructure to run that study at scale. We welcome the collaboration.18
Conclusion
Students are already using AI. They are using it responsibly. But they are not yet using it effectively.
The gap is not ethical. It is technical. And unlike many structural challenges in education, this one appears to be solvable, with the right feedback loops, built into the tools students are already using.
How to cite this report
StudyFetch Research Team. (2026). What 4.9 million student interactions reveal about AI literacy and learning. StudyFetch. studyfetch.com/research/ai-literacy-2026
Acknowledgements
We thank the 144,544 students whose interactions with Spark.E made this analysis possible, and the teachers and administrators who partner with us to put AI literacy at the center of their classrooms. This report draws on three internal research memos written between March and April 2026 covering the AI literacy scoring system, the 10,000-question quiz study, and the Learn Engine correlation analysis.
Appendix
Appendix A — Scoring rubric
Prompting: “Did you give the AI enough to actually help?”
| Grade | What it means |
|---|---|
| A (4) | Clear intent, good context. The AI knows exactly what to do. |
| B (3) | Clear enough to get a useful response. |
| C (2) | Vague or missing context. The AI has to guess. |
| D (1) | Unclear, random characters, or no real intent. |
Responsibility: “Are you using AI to learn, or to avoid learning?”
| Grade | What it means |
|---|---|
| A (4) | Shows own work, asks conceptual questions, uses AI as a thought partner. |
| B (3) | Wants to understand the material, not just get answers. |
| C (2) | Asks for direct answers with little effort shown. |
| D (1) | Asks the AI to do their work without participating. |
When study materials are loaded into the chat, short prompts like “Summarize this” or “Explain page 5” count as good prompting because the context is already present in the session. The two scores are independent: a student can write a perfectly clear prompt that asks the AI to write their essay (A on prompting, D on responsibility), or show deep engagement while being vague about what they need (A on responsibility, C on prompting). Separating the dimensions lets us diagnose the right problem.
Worked examples across the matrix
“I'm writing an essay on the causes of WWI. My thesis is that alliance systems were the primary cause. Can you help me think of a counterargument to strengthen my paper?”
“Can you explain the difference between mitosis and meiosis in a table format? I have a test tomorrow and I keep mixing them up.”
“I think the answer to #3 is 42 but I'm not sure about my approach. Did I set up the equation right?”
“Help with chemistry.”
“Write me a 5 paragraph essay about the Great Depression for my history class.”
Appendix B — Methodology
Sample and study period. All figures in this report draw from 4,910,114 graded messages sent by 144,544 students between January 20 and March 10, 2026, a 50-day window. Messages are scored in real time as students interact with the Spark.E AI tutor. Simple acknowledgements (“ok,” “thanks,” “got it”), very short messages, and quiz answer submissions are not graded; about 35% of messages fall into this skipped category. The remaining 65% are graded on the prompting and responsibility rubrics in Appendix A.
Learn Engine sampling design. For the Learn Engine correlation analysis (Tables 3–4, Figures 8–10), we sampled 200 students per AI literacy grade (A, B, C, D) for each of the two dimensions (prompting and responsibility). We ran the sampling and analysis 10 times and averaged the results. Only topics with at least one student interaction are included. The D-responsibility bucket contains 63 students (11 with K-score data), because very few students sustain a D average on responsibility; results for that cell should be interpreted with caution.
Quiz study. The 10,000-question study was drawn from 536,362 total quiz questions where students used the AI chat sidebar during a StudyFetch quiz session. Each chat message was scored on prompting (1–4) and responsibility (1–4). The 22.1% baseline first-attempt correct rate for students who answered before chatting was computed on the first 30,000 questions. Students who open the chat first may self-select by recognizing harder questions, so the comparison includes selection bias.
Statistical note. All reported correlations are observational. We do not attempt formal causal identification. Where a bucket contains small samples (notably D-responsibility), we flag it explicitly and avoid strong claims. Rates reported as percentages with a decimal place (e.g., 31.9%, 71.1%) are empirical rates from the sample; rates reported without a decimal (e.g., 25%, 60%) are rounded for readability.
Classifier validation. Prompting and responsibility scores are produced by StudyFetch's AI Literacy rubric in real time. No human validation study has been conducted to date; the rubric was calibrated iteratively during development against a set of curated example interactions covering the 4×4 grade combinations in Appendix A. A formal inter-rater reliability study is a planned next step.
Example classifier prompt (prompting dimension).
You will be given a single student message from a chat with an AI tutor, plus any study materials attached to the chat session. Score the student's PROMPTING on a 1-4 scale: - 4 (A): Clear intent, good context. The AI knows exactly what to do. - 3 (B): Clear enough to get a useful response. - 2 (C): Vague or missing context. The AI has to guess. - 1 (D): Unclear, random characters, or no real intent. When study materials are already attached, short prompts that reference that material (e.g. "summarize this", "explain page 5") should score at least B, because the context is already present in the session. Return a single integer 1-4 and a brief explanation (one sentence).
About StudyFetch
StudyFetch is a technology company building AI-native learning products designed to strengthen comprehension and connect education with workforce readiness. The platform supports students, educators, and organizations in building durable, real-world skills, and is used by more than 7 million people globally, across high school, college, medical school, graduate programs, and professional contexts. Spark.E, our AI tutor, is one of several products on the platform; it turns each student's own course materials — lecture notes, slides, textbooks, syllabi — into adaptive flashcards, practice exams, and a tutor that meets them where they are. The Learn Engine continuously tracks mastery across more than 30,000 active topic clusters and updates as students learn, so practice is calibrated to what each student needs next.
We build for learning outcomes, not engagement metrics. StudyFetch does not give direct answers to homework, and every student message is graded in real time on how well it supports learning — the same AI Literacy rubric used throughout this report. That product design is why responsible-use rates among StudyFetch students are as high as the data shows; it is also why we believe AI literacy can be taught, and that the right feedback loops change behavior quickly.
Research, partnerships, and press
StudyFetch publishes research on how students actually use AI to learn. We work with social scientists, learning researchers, and academic institutions to study the causal link between AI literacy and learning outcomes at scale. If you are a researcher interested in collaborating, or a journalist covering AI in education, we welcome the conversation.
Endnotes
- 4,910,114 graded messages from 144,544 students between January 20 and March 10, 2026. 92.9% of messages scored 3 or 4 on responsibility; 0.08% (3,967 of 4,910,114) were flagged in dishonesty-related categories.
- 0.5% of students with five or more graded messages sustain an A-level prompting average (≥3.5 on the 4-point scale). 55.3% of students average between 1.5 and 2.5 on prompting across all their messages.
- Free response correct rates: 31.9% (174 / 545) for responsibility Score 4 vs 3.3% (9 / 271) for Score 1. Ratio: 9.6×.
- Prompting improvement curve: 25% of messages reach C-level in the first five messages, 26% through messages 6–10, 60% in messages 11–15, and 73% through messages 31–50.
- Learn Engine analysis: prompting-A correct rate 71.1% vs prompting-D 64.5%; responsibility-A correct rate 72.1% vs responsibility-D 61.5%. Both dimensions show monotonic decline across grades.
- AI Literacy scoring rubric assigns prompting and responsibility each a score of 1–4 in real time as students interact with Spark.E. Approximately 35% of messages (acknowledgements, very short messages, quiz answer submissions) are not graded; the remaining 65% are graded.
- Education level is self-reported during onboarding and is set for roughly 65% of graded messages. Post-calibration data only.
- 10,000-question sample: Score 4 first-attempt correct rate 33.5% (311 / 927); Score 1 first-attempt correct rate 14.5% (103 / 711); ratio 2.3×. Score 4 mastery rate 54.4% vs Score 1 26.9%; ratio 2.0×. Score 4 average best grade 63.6 vs Score 1 42.6; difference 21.0 points.
- Confidence analysis sample sizes: “I don't know” includes 169 Score 1 attempts and 147 Score 4 attempts; Low confidence includes 226 and 254; Medium confidence includes 253 and 442. Engaged students outperform disengaged peers at every confidence level.
- 190 students with an average prompting score below 1.5 on their first 10 messages who subsequently sent 50 or more total messages. 86.8% reached an average of 1.5 or above on their last 20 messages. Small sample; some improvement likely reflects regression to the mean, though the sustained level through messages 31 to 100 suggests genuine improvement.
- Improvement defined as a change of +0.25 or more comparing first 10 vs last 10 message averages; decline defined as −0.25 or more. Remaining 1% could not be classified.
- StudyFetch Learn Engine: ELO-like K-score that updates continuously across flashcards, practice exams, and AI tutor sessions. The system currently tracks more than 30,000 active topic clusters, part of more than 100 million total topics. The Learn Engine optimizes for the human being able to do the work, not for the machine completing the work.
- The D-responsibility bucket contains only 63 students total and 11 with K-score data (vs 83 with K-scores for A, 101 for B, 59 for C), because very few students consistently score D on responsibility. Interpret D-responsibility numbers with caution.
- Prompting A–D correct rate gap: 6.6 percentage points. Responsibility A–D correct rate gap: 10.6 percentage points. K-scores decline monotonically from A to D on both dimensions.
- Average questions answered: prompting A = 150.0, D = 75.6; responsibility A = 158.5, D = 50.1.
- Students with study materials attached averaged 2.53 on prompting vs 2.38 without (+0.15).
- First-attempt correct rate for students who answered before chatting: 22.1% on the first 30,000 questions in the sample. Students who chatted before their first attempt answered correctly at a higher rate. Students who opt to open the chat first may self-select by recognizing harder questions, so the comparison includes selection bias.
- Observational data only. Controlled studies are required to establish causality between AI literacy and learning outcomes.

StudyFetch Research Team